If you’ve heard the term RAG or “Retrieval Augmented Generation” lately, you may have asked yourself something like “What is that?” or “How did such a ridiculous acronym get so popular?”
I can’t answer to the way it was named, but I can tell you this: One of the core pieces of RAG systems is semantic search, which helps map the underlying meaning (semantics) of a search query to the closest-related meaning of a set of documents in a database.
In this post, we’ll go over how to implement basic semantic search with the HONC stack, using Hono as an api framework, Neon postgres as a database, Drizzle as an ORM, and Cloudflare Workers as the serverless deployment platform.
We’ll build a small semantic search engine for Cloudflare’s documentation, giving us a system that understands the meaning behind search queries, not just keyword matches.
Follow along on GitHub
Here is a repo with the code examples for this post
A Conceptual Primer
Before we get started, let’s go over some basic concepts. This will be especially helpful if you’re not already familiar with vectors and embeddings.
Vectors
For our purposes, vectors are lists of numbers, like [1, 2, 3, 4, 5].
Vectors are described in terms of their length. An example of a vector of length two would be [.68, .79] and a vector of length three would look like [.883, .24, .6001]. Simple!
When vectors are all the same length, you can compare and manipulate them in interesting ways, by adding them together, subtracting them, or finding the distance between them.
All of this will be relevant in a bit, I promise 🙂
Embeddings
Put shortly, embeddings are vector representations of the meanings of words and phrases… But. Well. That’s a little abstract.
My favorite analogy for why these are useful and how they work comes from from AI researcher Linus Lee. He draws a comparison to colors. There’s a difference between describing a color with a name, like “blue”, versus with an RGB value rgb(0, 0, 255). In this case, the RGB value is a vector of length three, (0, 0, 255).
If we wanted to mix some red into the named color "blue" and make a new color that’s just a little more purple, how would we do that?
Well, if all we have is the name of the color, there’s not much we can do. We’d just invent a new color and give it a new name, like "purpleish blue". With an RGB value, though, we can simply “add” some red:
rgb(20, 0 , 0) + rgb(0, 0, 255) = rgb(20, 0, 255)
Because we chose to represent our color with vectors of numbers, we can do math on it. We can change it around, mix it with other colors, and have an all around good time with it.
Embeddings are a way for us to do this kind of math on human language. Embeddings are vectors, like RGB values, except they’re much larger.
How would you “do math on human language” though? Borrowing an example from the trusty Internet, let’s say we have a vector for the word "king", and a vector for the words "man" and "woman".
If we subtract the vector for "man" from the vector for "king" , then add the vector for the word "woman". What would you expect we get?
Wild enough, we would get a vector very very close to the one for the word "queen".
Pretty neat, huh?
Vector Search
Searching across vectors usually refers to looking for vectors that are similar to one another.
In this case, we think of similarity in terms of distance. Two vectors that are close to one another are similar. Two vectors that are far apart are different.
So, in a database that stores vectors, we can calculate the distance between an input vector, and all vectors in the database, and return only the ones that are most similar. In this post, you will see a reference to “cosine similarity”, which is a way to calculate the distance between two vectors. So, don’t get freaked if we start talking about cosines.
Basically, instead of looking for exact matches or keyword matches for a user’s query, we look for “semantically similar matches” based off of cosine distance.
How Do We Start?
To perform semantic search, we need:
- a database that supports vector embeddings
- a way to vectorize text
- a way to search for similar vectors in the database
To be entirely frank, the hardest part of building semantic search is knowing how to parse and split up your target documents text into meaningful chunks.
I spent most of my time on this project just pulling down, compiling, and chunking the Cloudflare documentation. After that, the search part was easy-peasy. I will gloss over the tedious parts of this below, but I’ve provided a link to the script that processes the documentation, for anyone who is interested.
That said, let’s go over the stack and database models we’ll be using for the actual searching part.
The Stack
We want to expose a simple API for users to search the Cloudflare documentation. Then we want some tools for storing the documents and their embeddings, as well as querying them.
Here’s the stack we’ll be using for all of this:
- Hono: A lightweight web framework for building typesafe APIs
- Neon Postgres: Serverless postgres database for storing documents and vector embeddings
- OpenAI: To vectorize documentation content and user queries
- Drizzle ORM: For constructing type-safe database operations
- Cloudflare Workers: To host the API on a serverless compute platform
Setting up the Database
First, we define a schema using Drizzle ORM.
When we craft our database models, we have to think of what kind of search results we want to return. This leads us to the idea of “chunking”, which is the process of splitting up the text into smaller chunks.
The logic is: We don’t want to match a user’s query to entire documents, because that would return a lot of irrelevant results. Instead, we should split up each documentation page into smaller chunks, and match the user’s query to the most semantically similar chunks.
Since we’re working witha relational database, we can define a schema for the documents and chunks, where each document can have many chunks.
So, our Drizzle schema defines two main tables:
documents: Stores the original documentation pageschunks: Stores content chunks with their vector embeddings
export const documents = pgTable("documents", {
id: uuid("id").defaultRandom().primaryKey(),
title: text("title").notNull(),
url: text("url"),
content: text("content"),
hash: text("hash").notNull()
});
export const chunks = pgTable("chunks", {
id: uuid("id").defaultRandom().primaryKey(),
documentId: uuid("document_id")
.references(() => documents.id)
.notNull(),
chunkNumber: integer("chunk_number").notNull(),
text: text("text").notNull(),
embedding: vector("embedding", { dimensions: 1536 }),
metadata: jsonb("metadata").$type<Array<string>>(),
hash: text("hash").notNull()
});Once we define a schema, we can create the tables in our database. If you’re following along on GitHub, you can run the commands below to create the tables. Under the hood, we use Drizzle to generate migration files and apply them to the database.
pnpm db:generate
pnpm db:migrateNow, with our database set up, we can move on to processing the documentation itself into vector embeddings.
Processing Documentation
The heart of our system is the document processing pipeline. It’s a bit of a beast.
I’m going to move through this quickly, but you can see the full implementation in
./src/scripts/create-vectors.ts.
This script:
- Takes HTML documentation files as input
- Uses GPT-4o to clean and chunk the content
- Generates embeddings for each chunk
- Stores everything in our Neon Postgres database
Once this runs, we have a database full of document chunks and their embeddings, and we can move on to building the search API. Probably the most interesting part of this script is how we use GPT-4o to clean and chunk the content. In some cases, this might be cost prohibitive, but for our use case, it was a no-brainer. We only need to run this once, and it was a lot smarter than any heuristics I would’ve defined myself.
If you’re following along on GitHub, I commend you. You can run these commands to process the documentation. (Please file an issue if you run into any problems.)
# Process the Cloudflare documentation
cd data
bash copy-cf-docs.sh
cd ../
# Create the vector embeddings
pnpm run vectors:createThe Search API
When a user makes a search request, we do the following:
- Convert their query into a vector embedding
- Use cosine similarity to find the most relevant chunks for their query
- Return the top matches back to the user
Why convert their query into a vector embedding? We want to find the most semantically similar chunks, so we need to represent their query in the same format as our database chunks.
The search endpoint is surprisingly simple thanks to Hono.
We define a GET route that takes query and similarity parameters.
app.get("/search", async (c) => {
// ...
// Parse query parameters
const query = c.req.query("query");
const similarityCutoff =
Number.parseFloat(c.req.query("similarity") || "0.5") ?? 0.5;
// ...
});Then, we make a request to OpenAI to create an embedding for the user’s search query.
app.get("/search", async (c) => {
// ...
// Initialize the OpenAI client
const openai = new OpenAI({ apiKey: c.env.OPENAI_API_KEY });
// Create embedding for the search query
const embeddingResult = await openai.embeddings.create({
model: "text-embedding-3-small",
input: query
});
const userQueryEmbedding = embeddingResult.data[0].embedding;
// ...
});Finally, we craft a similarity search based on the cosine distance between the query embedding and each chunk’s embedding.
Here, the drizzleSql helper is the sql helper exported by Drizzle, which has been renamed for clarity.
It allows us to construct type-safe sql expressions.
app.get("/search", async (c) => {
// ...
// Craft a similarity search query based on the cosine distance between
// the embedding of the user's query, and the embedding of each chunk from the docs.
const similarityQuery = drizzleSql<number>`1 - (${cosineDistance(chunks.embedding, queryEmbedding)})`;
// Search for chunks with similarity above the cutoff score
const results = await db
.select({
id: chunks.id,
text: chunks.text,
similarity: similarityQuery
})
.from(chunks)
.where(drizzleSql`${similarityQuery} > ${similarityCutoff}`)
.orderBy(drizzleSql`${similarityQuery} desc`)
.limit(10);
// ...
});That leaves us with a list of chunks that are semantically similar to the user’s query! We can choose to render these results however we see fit.
When we use Fiberplane to test the search API, we can see the timeline of the request, including the embedding generation, similarity search, and result rendering. We can also see the raw SQL that was executed, which is a little unwieldy since we’re dealing with vectorized queries:
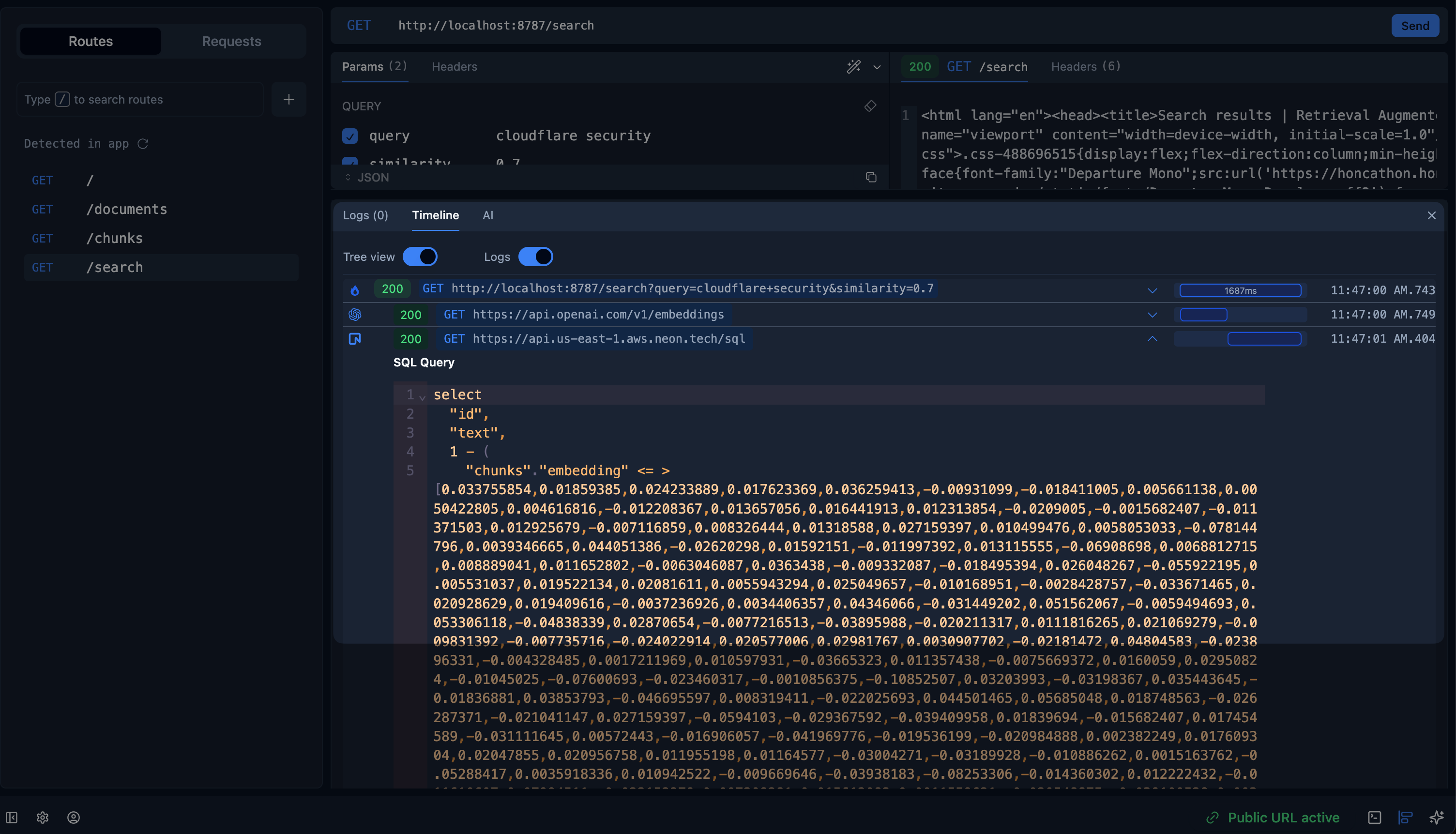
And that’s it! We’ve built a semantic search engine with the HONC stack.
The Magic of Vector Search
What makes this more powerful than regular text search? Again, vector embeddings capture semantic meaning. For example, a search for “how to handle errors in Workers” will find relevant results even if they don’t contain those exact words.
Neon makes this simple, easy, and scalable by allowing efficient similarity searches over high-dimensional vectors out of the box.
However, that doesn’t mean that vector search is the only tool for retrieval. Any robust system should consider the trade-offs of vector search vs. keyword search, and likely combine the two.
Deployment
See it in action
Here is a live demo of the search API
Deploying to Cloudflare Workers is straightforward. We just push the code and set the secrets.
# Set your secrets
wrangler secret put DATABASE_URL
wrangler secret put OPENAI_API_KEY
# Deploy
pnpm run deploy
Conclusion
If you’re looking for a quick way to get up and running with semantic search, this should give you a solid starting point.
Worth noting: there are a lot of libraries out there that can take care of the heavy lifting of building RAG systems. At Fiberplane, we’ve built smaller systems with Llamaindex and Langchain, but for simpler use cases, I found myself wading through documentation and GitHub issues more than I’d like. A higher-level library can be very helpful for bigger applications, but for something this simple, I think the core concepts are valuable to implement and understand.
To that end, the full code for everything in this post is available on GitHub, and you can adapt it for your own needs.
Get the code on GitHub
Here is the repo with the full code for this post
Otherwise, don’t forget to check out the HONC stack for more examples of building with Hono, Drizzle, Neon, and Cloudflare.