I was really excited when I came across Hono. I think the API is elegant in its simplicity, and I’ve found it—in my admittedly limited experience—to be a sturdy foundation for moderately complicated backends.
In short, Hono is fast, flexible, and honestly fun to work with. Templates will get you started in a dozen different runtimes and frameworks, and there are a multitude of plugins and middleware to facilitate integration with third-party tools.
How do all of these pieces fit together?
While project constraints and implementation details will vary, most data APIs need to satisfy three key requirements:
- A way to persist queryable data, typically a database,
- To define and regulate how data moves between application layers,
- And to safeguard against malicious activity and user error.
When you’re just getting started with a framework, ostensibly simple steps like configuring the database or spinning up a validation layer can become grueling hurdles to adoption. Enter HONC, a stack made for lightweight data APIs on the edge.
HONC stands for Hono, Drizzle ORM, Neon DB, and Cloud(flare). It’s a collection of technologies dedicated to performance and type-safety, developed by Fiberplane as a template for non-trivial Hono APIs.
0 to 60 with the HONC app
HONC is more of a design philosophy than a rigid doctrine. You can use the create-honc-app CLI to download a project with either a Neon, D1, or Supabase DB. Drizzle plays a pivotal role by managing seeding and migrations, and decoupling the stack from the database. As the source of truth for (DB) type definitions, it can also be the foundation of your type system and runtime validation.
This gets us from 0 to 60, but what about the 80/20, or at least 70/30? Implementation details like validation layers and rate limiting are too contingent on business requirements to usefully include in a template, but when you pick up a library for the first time, having robust examples is a game-changer.
Mocking a (moderately) advanced data API
To simulate what happens when a design philosophy collides with project constraints, Fiberplane asked me to build a simple mock-data API called Placegoose (like JSONPlaceholder) using the HONC stack.
Fiberplane Studio is an API testing and debugging tool—like the Inspector panel in your browser—that we’ll be using to inspect requests, logs, and database calls. Check out the docs here.
A mock-data API’s functional requirements are robust enough to involve all key aspects of API development, but not so complicated as to be distracting. At a bare minimum, they serve relational data via multiple application layers, but they can be usefully enhanced with features like validation and rate limiting.
To give ourselves some concrete parameters, we settled on a handful of features that most production-ready data APIs must implement:
- A database with an ORM or custom adapter layer
- Validation and business logic
- Error handling and rate limiting
- A lightweight markdown-based frontend for docs
This is the first article in a series that will cover 1) building the app, 2) deploying to production, and 3) rendering a front end. We hope the series has something to offer more- and less-experienced devs alike, but we’ll be focused on patterns, helpers, and gotchas, so we won’t be explaining basic data API or TypeScript patterns.
Getting up and running with HONC
To get started, we’ll download the HONC D1 template and install dependencies. The project doesn’t need any additional configuration to run locally.
npm create honc-app@latest
npm iIn order to connect to a remote DB, you’ll need to update the D1 section in your wrangler.toml (the Cloudflare Worker config file). We’ll cover this in detail in the next article. For now, take a moment to get acquainted with the config, and update the database name and ID to match your project.
[[d1_databases]]
binding = "DB"
database_name = "placegoose-d1"
# Can be anything for local development
# Must be updated when connecting to a remote DB
database_id = "local-placegoose-d1"
migrations_dir = "drizzle/migrations"The binding value is the key used to access the database from within the app.
If you choose to rename it, be sure to keep the Bindings property of AppType in sync for proper intellisense and type propagation.
type AppType = {
Bindings: {
// Global type from @cloudflare/workers-types
DB: D1Database;
};
};
// Any instances connecting to the DB must be typed
const app = new Hono<AppType>();If you’re new to (or ambivalent about) TypeScript, don’t worry: Despite this being a fully-integrated TypeScript project, AppType is one of the only types you’ll need to define and manage yourself! In fact, this is it for project setup, so why don’t we take a look at the HONC stack’s lynchpin: Drizzle ORM.
Type-safe database management with Drizzle ORM
As I alluded to earlier, Drizzle does a lot of heavy lifting for us. In any project with a database, we need to manage table schemas and migrations, bridge the gap between JavaScript and SQL syntax, and validate data going into the DB.
That’s a non-trivial task, especially for a small team or solo dev, and demands a lot of discipline to build and maintain. Drizzle offers all of this in a type-safe package that lets us derive types and validation models directly from table definitions.
This schema-first approach is meant to ensure that updates are reflected across the stack, meaning fewer files to update and fewer migration bugs.
Defining a single source of truth
The HONC template comes with a single table definition (db/schema.ts) that demonstrates how to require a column, default a value, and run raw SQL.
By default, Drizzle names columns after the keys in your table definitions. For seamless translation between camel and snake case, take advantage of Drizzle’s automatic case conversion.
We’ll update this file to describe the tables and types we need, in this case Gaggles, Geese (possibly belonging to a gaggle), and Honks (definitely belonging to a goose).
This gives us a chance to check out foreign keys (references), and share common column definitions (like primary keys or metadata) between tables.
import { integer, sqliteTable, text } from "drizzle-orm/sqlite-core";
const metadata = {
id: integer({ mode: "number" }).primaryKey()
};
export const gaggles = sqliteTable("gaggles", {
...metadata
});
export const geese = sqliteTable("geese", {
...metadata,
// Creating a Foreign Key
gaggleId: integer({ mode: "number" }).references(() => gaggles.id)
});Tables also directly expose Insert and Select types inferred from the rules you’ve set for columns and keys. Note that the SQL methods and features available (like enums) are syntax-specific.
const metadata = {
id: integer({ mode: "number" }).primaryKey()
};
export type GooseSelect = typeof geese.$inferSelect;
export const geese = sqliteTable("geese", {
...metadata,
gaggleId: integer({ mode: "number" }).references(() => gaggles.id),
name: text().notNull(),
isMigratory: integer({ mode: "boolean" }).notNull().default(true),
mood: text({
enum: ["hangry", "waddling", "stoic", "haughty", "alarmed"]
})
});
// type GooseSelect = {
// id: number;
// gaggleId: number | null;
// name: string;
// isMigratory: boolean;
// mood: "hangry" | "waddling" | "stoic" | "haughty" | "alarmed" | null;
// }If deployed effectively, these types will safeguard our data layer from code that tries to insert a malformed row. This doesn’t protect our API from bad data though, and it relies on comprehensive and disciplined typing throughout the app.
To keep compile- and run-time types in sync, we’ll create a validation layer using the drizzle-zod plugin.
We’ll explore this in greater detail in the validation section, but first we need to seed our database!
Seeding the database at scale
After I started working on the app, the HONC template was updated to use Drizzle’s new pRNG drizzle-seed library. Drizzle Seed uses your table models to programmatically generate seed data and populate the database.
To create the seed data, available in the repo, I fed the table models to a generative AI tool, making sure to test output at a small scale before dumping results into a json file. This was reasonably effective given that I only needed 500 rows, but obviously fragile, and somewhat tedious.
Placegoose does not currently use drizzle-seed, but this is how I would refine data generation for the Gaggles table. While not exhaustive, the helper functions that Drizzle provides are robust enough to support data like blog posts, contact information, or job listings.
import * as schema from "/src/db/schema.ts";
const db = drizzle(client);
await seed(db, {
gaggles: schema.gaggles
// ...
}).refine((f) => ({
gaggles: {
count: 10,
columns: {
name: f.fullName(),
territory: f.weightedRandom([
{ weight: 0.5, value: f.city() },
{ weight: 0.5, value: f.default({ defaultValue: null }) }
])
}
}
// ...
}));With our table models and seeding refinements (or seed data) defined, we just need to 1) create a local database, 2) generate and apply the initial migration, and 3) run the seed script. The HONC template includes a package script that chains these operations together, making it as easy as:
npm run db:setupManaging request data
Now that we have some data in the DB, we can start writing and testing endpoints! Hono’s approach to modular routes will be familiar to anyone that’s worked with Express: Just create a new Hono instance, chain whatever middleware and handling logic you need, and pass the instance as the second argument of Hono.route.
import { Hono, type Context } from "hono";
import { cors } from "hono/cors";
import { instrument } from "@fiberplane/hono-otel";
const app = new Hono();
// Ensure the API is publicly accessible.
// For more, see MDN's docs on CORS.
app.use("*", cors());
const gagglesRoute = new Hono();
// This handler will not be inferred in the gagglesRoute type
gagglesRoute.get("/:id", (c: Context) => {
return c.text("Not yet implemented", 418);
});
app.route("/gaggles", routes.gaggles);
// Have Fiberplane client inspect traces
export default instrument(app);Hono recommends chaining methods directly to the constructor call for optimal type inference and RPC behavior. I chose to separate method calls because this project doesn’t benefit from the additional type safety, and I find them easier to read.
Writing all our handlers in the index file would quickly get out of hand though, so we should add a routes directory with a file for each resource, limiting the cognitive load in a given file.
The next steps are to develop the handler logic and validation, filling in routes one endpoint at a time. This is where we’ll start to run into errors, so remember to add a simple catch-all error handler. We’ll cover error processing in more detail later, but we don’t want our app to crash while we work!
app.onError((error, c) => {
console.error(error);
return c.text("Something went wrong!", 500);
});Visualizing the data pipeline with Fibeplane Studio
If you’re following along locally, take a moment to launch your app and the Fiberplane Studio by running
npm run devandnpm run fiberplanein separate terminals!
To debug requests that go wrong, and to optimize services that are working as expected, we can use the Fiberplane Studio. By wrapping our app with the instrument method, we give the Fiberplane client access to request traces, which are then displayed in the Studio.
Built specifically for Hono apps, Fiberplane automatically detects new routes and configures request templates with path parameters.
As you test (and re-test) services, console logs of all levels will appear in the Logs panel (hotkey G + L), and we can inspect the request Timeline (G + T) to view all traces, including D1 database calls.
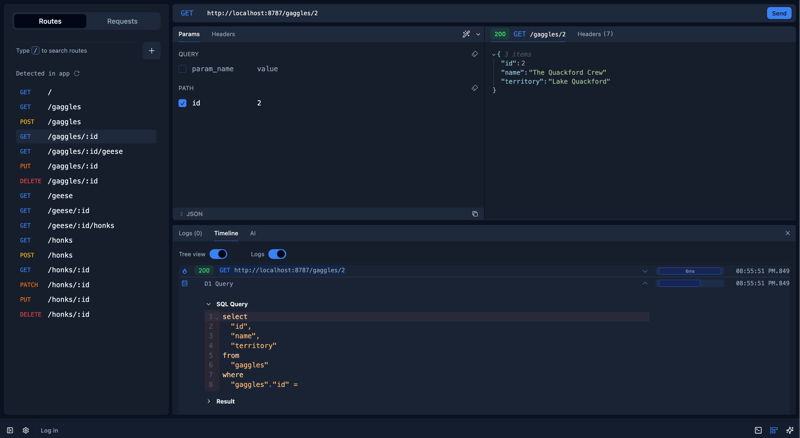
Like most mainstream HTTP clients you can “replay” requests, making it a piece of cake to rapidly test defined happy and sad paths after refactoring an endpoint. By integrating logs and more robust traces though, I found that Fiberplane cut down on some of the back-and-forth between my HTTP client and my terminal.
Having this comprehensive insight into the request lifecycle built into my HTTP client was helpful throughout development, but especially when building in more complex features like validation, and when trying to optimize handler performance.
Querying the bound databases
With telemetry set up, we’re ready to start querying and serving data! First, we need to connect to the database by calling the drizzle initializer, which expects a D1 client bound to the app.
This is where the Bindings property on AppType comes in. Hono exposes bindings and other environment values through the Context object, whose typing is inherited from its immediate parent.
In the source code I abstract the call in order to reduce repetition, but the following examples will show it inline for clarity. Though tempting, I chose not to use a singleton because there didn’t seem to be much benefit for such a simple service and short-lived service.
The initializer also accepts an optional config argument. Since we’re making use of Drizzle’s auto-casing, we need to specify that the client should expect snake case from the DB.
import { drizzle } from "drizzle-orm/d1";
import { Hono } from "hono";
type AppType = {
Bindings: {
// Global type we get from @cloudflare/workers-types
DB: D1Database;
};
};
const gagglesApp = new Hono<AppType>();
// Get all Gaggles
gagglesApp.get("/", async (c) => {
// We get our DB binding from Context
const db = drizzle(c.env.DB, {
// This must be set for Drizzle to automatically
// translate between snake and camel case
casing: "snake_case"
});
// Drizzle inference tells us is type Gaggle[]
const gaggles = await db.select().from(schema.gaggles);
return c.json(gaggles);
});
export default gagglesApp;Drizzle ORM aims to be a lightweight abstraction over SQL, so query construction is fairly intuitive. Statements are represented as chains of keywords, and Drizzle exports operators as flavor-specific helper methods.
Enforcing Drizzle types at run-time
To keep compile- and run-time types in sync, we’ll create a validation layer using the drizzle-zod plugin. It gives us constructors that build Zod schemas from Drizzle table models. As with the types exposed on table models, there is an Insert and a Select option.
import { createInsertSchema } from "drizzle-zod";
import * as schema from "./schema";
export const ZGaggleInsert = createInsertSchema(schema.gaggles, {
name: (schema) => schema.name.min(1),
territory: (schema) => schema.territory.min(1)
});Initially I was worried this might be limiting, but Drizzle makes it easy to extend or override field definitions. Zod accepts empty string values by default, so I made use of this feature to require that name fields were at least populated.
Zod is an awesome schema library you can use to keep your types and validation in sync. I won’t be discussing how to use the library here, but I encourage you to check out the docs if you haven’t already!
I chose to export all the Zod schemas from a single file in the db directory, mostly to keep them out of the schema file exports, but also because I’ve found that keeping validators centralized and close to where they’re used—in this case the data layer—helps maintain a clear distinction between different validation layers.
Validating request data
Since the app is meant to serve mock data, a more defined database validation layer wasn’t necessary, but we do want to validate incoming payloads.
The Insert schemas we generated from our tables are fine for the DB, but we don’t want to allow users to specify ID values themselves, as this can quickly get messy. We also want to prevent users from updating which goose honked a honk, because what kind of world would that be!
To deal with this, we can create an additional validation layer for request payloads in a new dtos directory. DTOs (Data Transfer Objects) are just logic that regulates how data moves across layers.
export const ZGaggleInsertPayload = ZGaggleInsert.omit({
id: true
});
export const ZHonkInsertPayload = ZHonkInsert.omit({
id: true
});
export const ZHonkUpdatePayload = ZHonkInsertPayload.omit({
gooseId: true
});Hono’s validator middleware makes it easy to use these schemas (or any logic) to validate request data. Targets include—but aren’t limited to—route parameters, query values, and json (body). The middleware takes the target (e.g., “param”) and a validation callback, and exposes valid results type-safely via the app Context.
// Update Gaggle specified by id
gagglesApp.put(
"/:id",
validator("param", (params, c) => {
const idParam = params.id;
if (!/^[1-9]\\d*$/.test(value)) {
throw new HTTPException(400, {
message: "ID values must be positive integers",
});
}
return {
id: Number.parseInt(value);
};
}),
validator("json", (body, c) => {
// ...
}),
async (c) => {
// 'id' is known to be type "number"
const { id } = c.req.valid("param");
// ...
return c.json(updatedGaggle);
},
);Hono provides a Zod-specific validator helper (@hono/zod-validator), which takes care of the validation and error handling boilerplate. I found the library to be a useful reference, but by default it early-returns the response on error—including full Zod error details in the body.
You can override this behavior with a callback, but I opted to build my own solution in order to directly incorporate standardized error processing, and maintain a centralized error handling flow.
/**
* @returns Validation fn for Hono body validator, responsible
* for processing payload errors
*/
export function makeBodyValidator<T extends Zod.AnyZodObject>(schema: T) {
// _output is a utility key on Zod schema types
// that gives us the type of valid output
return (body: unknown): T["_output"] => {
const result = schema.safeParse(body);
if (result.success) {
// Return value must be consistent with shape of "body"
// Available through Context.req.valid
return result.data;
}
throw new HTTPException(400, {
message: "Invalid Payload",
cause: result.error
});
};
}I also wrote a simple function to format Zod error data so that it would be more useful for consumers. In retrospect, I should have called this in the body validator factory, and included the results in a custom error response.
I didn’t realize you could inject responses like this at the time though, and I chose not to extend Hono’s HTTPException in the interest of simplicity. Instead, I threw to the global error handler we’ll set up next.
Handling the sad path
Securing vulnerabilities and handling errors are critical components of API development, and we’ve already taken a few important steps: Drizzle lets us keep our type system slim, maintainable, and in sync with runtime validation, preventing typing bugs at compile-time.
We then use Hono’s validator middleware to enforce these data contracts at run-time, ensuring our handlers are working with valid data.
Responding to errors gracefully
When something goes wrong though, we need to communicate that to users and system maintainers in a way that’s helpful to each. While a detailed error log is useful to devs, it can be overwhelming to consumers, and can leak sensitive information about users or the system.
We can create a catch-all error handler using the Hono.onError method after all our route definitions. It gives us access to the error data and request context.
app.onError((error, c) => {
console.error(error);
// Handle formatted errors thrown by app or hono
if (error instanceof HTTPException) {
return c.json(
{
message: error.message
},
error.status
);
}
return c.json(
{
message: "Something went wrong"
},
500
);
});I typically prefer to centralize error processing because it makes it easy to create a consistent experience. You can create error boundaries wherever you’d like though, both with onError, and the specialized Hono.notFound handler. I’ve found this especially powerful when creating webhooks for multiple third-party services, which might have different error-handling requirements.
Using rate limiting to protect APIs from abuse
Securing our app isn’t just about data integrity though, it’s also about access. Now that our app is ready for consumers, we need to make sure that they all have fair access to the service. Rate limiters track how often users make a request—typically with a low-latency database like Redis—and reject requests if they occur too frequently within a set period.
Controlling how often services are accessed allows us to prevent users from hogging resources (maliciously or not), possibly slowing down and even crashing systems. If your service will be paywalled, some form of rate limiting is also the only way to enforce tiered access.
Since we’re using Cloudflare, we can take advantage of their new Rate Limiting bindings, now in open beta. This product handles both the rate limiting logic and data storage, based the configuration in your wrangler.toml. The calls we anticipate in this app are pretty cheap on the whole, so we can afford to be liberal with the rate limit and period.
# The rate limiting API is in open beta.
[[unsafe.bindings]]
name = "MY_RATE_LIMITER"
type = "ratelimit"
# An identifier you define, that is unique to your Cloudflare account.
# Must be an integer.
namespace_id = "1001"
# Limit: the number of tokens allowed within a given period in a single
# Cloudflare location
# Period: the duration of the period, in seconds. Must be either 10 or 60
simple = { limit = 100, period = 60 }After configuring it, we would call the binding’s limit method from a custom middleware to determine whether to proceed with a request. Under the hood, the rate limiter will query an in-memory DB with the provided key, and use the results to determine whether the client (represented by the key) is eligible to make additional requests in the current period.
It is recommended that you use a unique key for each user, like an ID, in order to ensure that each user gets the expected number of requests per period.
const { success } = await env.MY_RATE_LIMITER.limit({ key: "USER_ID" });In order to conform to the HTTP spec, rejected responses must include data related to the rate limit (like the retry-after header). Rather than implement the spec ourselves, we can lean on the rich ecosystem of third-party solutions that is beginning to emerge around Hono.
We’ll be using hono-rate-limiter, which is also compatible with other storage solutions (like Cloudflare KV and Redis). It manages all the rate limiting logic and storage for us, and formats responses to rejected requests appropriately. After installing, we only need to configure access to the binding and a key generation method.
// The Cloudflare rate limiter is distributed as a separate package
import { cloudflareRateLimiter } from "@hono-rate-limiter/cloudflare";
app.use("*", cors());
app.use(
cloudflareRateLimiter<AppType>({
rateLimitBinding: (c) => c.env.RATE_LIMITER,
keyGenerator: (c) => {
if (c.env.ENVIRONMENT === "production") {
// IPv4 or IPv6
return getConnInfo(c).remote.address ?? "";
}
return "localhost";
}
})
);Given the project’s limited scope—and the absence of defined users—we can use the request IP as the store key. Hono’s getConnInfo helper provides easy access to protocol and address info. Since users could legitimately share an IP though, having a unique token for each user (like a user ID) would be critical for a paywalled or heavily-trafficked API.
Building on the HONC stack
As a mock data API, Placegoose didn’t have a clear need for auth, or any kind of user or token management. Nonetheless, these are indispensable components of a secure data API. Hono offers some simple auth middleware, but if you need a more robust solution, or if you’re interested in rolling your own, I highly recommend Lucia Auth, an open source learning resource for session-based auth. They provide great guidelines, and examples for most common frameworks.
There was a lot I couldn’t cover in this article, but I hope that I’ve highlighted how the HONC stack can be used to address key requirements for lightweight data APIs, namely persistence, data integrity, and system security. Its minimal footprint helps it leverage performance on the edge, while its schema-first approach to typing streamlines system stability and maintainability.
Above all, the HONC stack is a strong but flexible framework, into which we can easily integrate important features like validation and rate limiting without losing type safety.
In the next article, Brett from Fiberplane will cover deploying Placegoose to production, including how to seed a remote D1. To conclude the series, we’ll discuss using markdown to render API docs with a custom layout.
Explore More with HONC
Learn more about building data APIs with the HONC stack.